
I often come across scenarios where the data that my application needs is available, but not in a format it can readily consume.
Cloud functions and other microservices really shine here. They can convert data from one form to another on demand and are generally very inexpensive. Since they are distinct execution contexts, they don’t have to match the consuming application’s tech stack. This frees them to use the language and libraries best suited to the job of conversion.
They also totally encapsulate (hide) the often inelegant conversion code, keeping the consuming application’s logic simple and focused.
One conversion I routinely need is from static websites to RESTful APIs. Let me illustrate with a couple of examples.
Example 1: Library Catalog Results
Take the example of my local library website. I want to create a browser plugin to notify online shoppers when a book they’re looking for is available at the library.

The library website provides a searchable online catalog. However, all the pages on the site are rendered server-side. The library doesn’t expose a public web API, either.
As it stands, my only option is to send my search query to the library’s server and add logic to my extension to parse the returned search results HTML.
But what if we instead create a cloud function that accepts a request from my browser extension, makes that network call to the library’s server, parses the returned HTML, and sends back a nicely formatted JSON response?
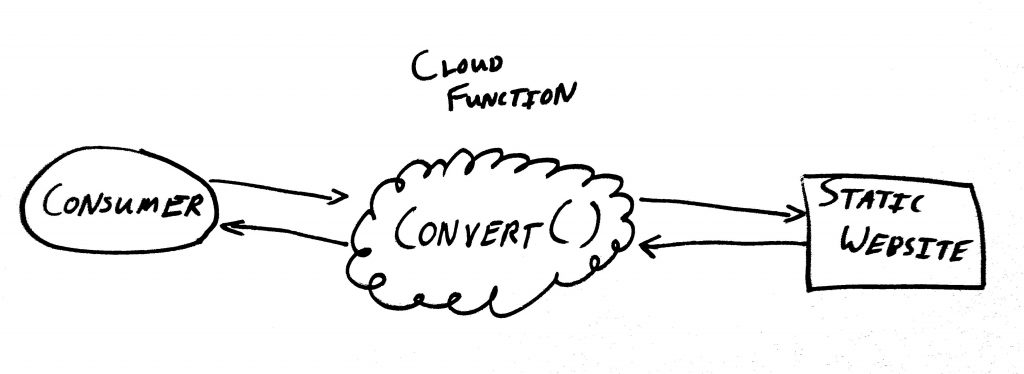
We will have effectively converted my local library’s statically rendered website into a RESTful JSON API.
Now that’s cool.
Here’s my cloud function code. (I use the Serverless framework with AWS Lambda for development and deployment).
import { APIGatewayProxyHandler } from 'aws-lambda';
import 'source-map-support/register';
import axios from 'axios';
import * as cheerio from 'cheerio';
import LIBRARY_SEARCH_URL from './endpoint';
const SELECTORS = {
RESULT_ENTRIES: '.results_cell',
TITLE_LINK: '.displayDetailLink',
THUMBNAIL: '.thumbnail img',
AUTHOR_NAME: '.INITIAL_AUTHOR_SRCH'
}
function queryLibrary(queryStr) {
const url = new URL(LIBRARY_SEARCH_URL);
url.search = `qu=${queryStr.replace(' ', '+')}`;
return axios.get(url.href);
}
function extractEntries(html) {
const $ = cheerio.load(html);
const results = $(SELECTORS.RESULT_ENTRIES);
const entries = [];
results.each((_, elem) => {
const rawThumbnailSrc = $(SELECTORS.THUMBNAIL, elem).attr('src');
const thumbnailSrc = rawThumbnailSrc.match('no_image.png') ? '' : rawThumbnailSrc;
const authorText = $(SELECTORS.AUTHOR_NAME, elem).text();
const authorName = authorText.replace('by', '').trim();
const result = {
title: $(SELECTORS.TITLE_LINK, elem).text(),
thumbnail: thumbnailSrc,
author: authorName
};
entries.push(result);
});
return entries;
}
export const query: APIGatewayProxyHandler = async (event, _context) => {
if (!event.queryStringParameters || !event.queryStringParameters.q) {
return {
statusCode: 400,
body: JSON.stringify({
message: 'No query provided'
}),
};
}
const res = await queryLibrary(event.queryStringParameters.q);
const resHTML = res.data;
const entries = extractEntries(resHTML);
return {
statusCode: 200,
body: JSON.stringify({
entries
})
};
}
And here’s an image of the JSON that my application gets back from the new API. This lists the first entries in the library’s catalog for the word computer.

Hopefully, you can already see the power in this microservice data-conversion architecture.
Example 2: Computer Science Faculty
Let’s say we’re building an app to recommend faculty mentors to potential graduate students at the University of Utah based on their research interests.
Fortunately, a list of faculty, complete with research blurbs and even contact information, is available on the university’s website.
Let’s follow the same pattern to create a web API. Here’s the code:
import { APIGatewayProxyHandler } from 'aws-lambda';
import 'source-map-support/register';
import * as cheerio from 'cheerio';
import Axios from 'axios';
const BASE_URL = 'https://www.cs.utah.edu';
const SELECTORS = {
FACULTY_ENTRIES: 'table#people:nth-child(3) tr.professor',
NAME: '#info > tbody > tr:nth-child(1) > td > h8',
OFFICE: '#info > tbody > tr:nth-child(2) > td:nth-child(2)',
PHONE: '#info > tbody > tr:nth-child(3) > td:nth-child(2)',
EMAIL: '#info > tbody > tr:nth-child(4) > td:nth-child(2)',
RESEARCH_INTERESTS: '#info2 > tbody > tr:nth-child(2)',
THUMBNAIL: 'img'
}
function extractFaculty(html) {
const $ = cheerio.load(html);
const faculty = [];
const entries = $(SELECTORS.FACULTY_ENTRIES);
entries.each((_, elem) => {
const facultyEntry = {
name: $(SELECTORS.NAME, elem).text(),
thumbnail: `${BASE_URL}${$(SELECTORS.THUMBNAIL, elem).attr('src')}`,
contactInfo: {
office: $(SELECTORS.OFFICE, elem).text(),
phone: $(SELECTORS.PHONE, elem).text(),
email: $(SELECTORS.EMAIL, elem).text(),
},
researchInterests: $(SELECTORS.RESEARCH_INTERESTS, elem).text()
};
faculty.push(facultyEntry);
});
return faculty;
}
export const harvest: APIGatewayProxyHandler = async (_, _context) => {
const res = await Axios.get(`${BASE_URL}/people/faculty/`);
const resHTML = res.data;
const faculty = extractFaculty(resHTML);
return {
statusCode: 200,
body: JSON.stringify({
faculty
})
};
}
Here’s the response from the new faculty API:

See the API working live here.
This bears many similarities to the library example. But do you notice differences?
Here’s an important one: Faculty change very rarely.
In the last example, it was necessary to poll the library website every time the cloud function received a search request from the consumer. However, this is often not the case.
In this faculty example, actually checking the static website for updates is rarely necessary. That frees us to cache the faculty data and simply poll the website for updates on an infrequent basis. Making this change decouples the data source from the consuming application. We’ve moved from one cloud function to two:

On the one hand, I like this decoupling because if you don’t control the data source (static website or otherwise), unannounced changes to it may require an update to the conversion code.
Without this decoupling, the conversion failure would likely be immediately apparent to an end user.
With it, the consuming application will probably continue to function just fine for a little while. This gives you time to update the conversion code with few hiccups.
The only downside, of course, is the extra complexity of making sure the cache is always fresh enough to be viable for your consuming application.
Conclusion
While this article is geared particularly toward converting from static websites to RESTful APIs, let me reiterate the general applicability of this cloud-function conversion pattern.
It provides a modular, targeted, independent environment in which to perform the sometimes complex conversion operations that are frequently required by modern applications.
(Originally published on Medium.)